Intermediate Text Representation Guided Text-to-Image Generation for Enhancing One-and-Only Alignment



Abstract
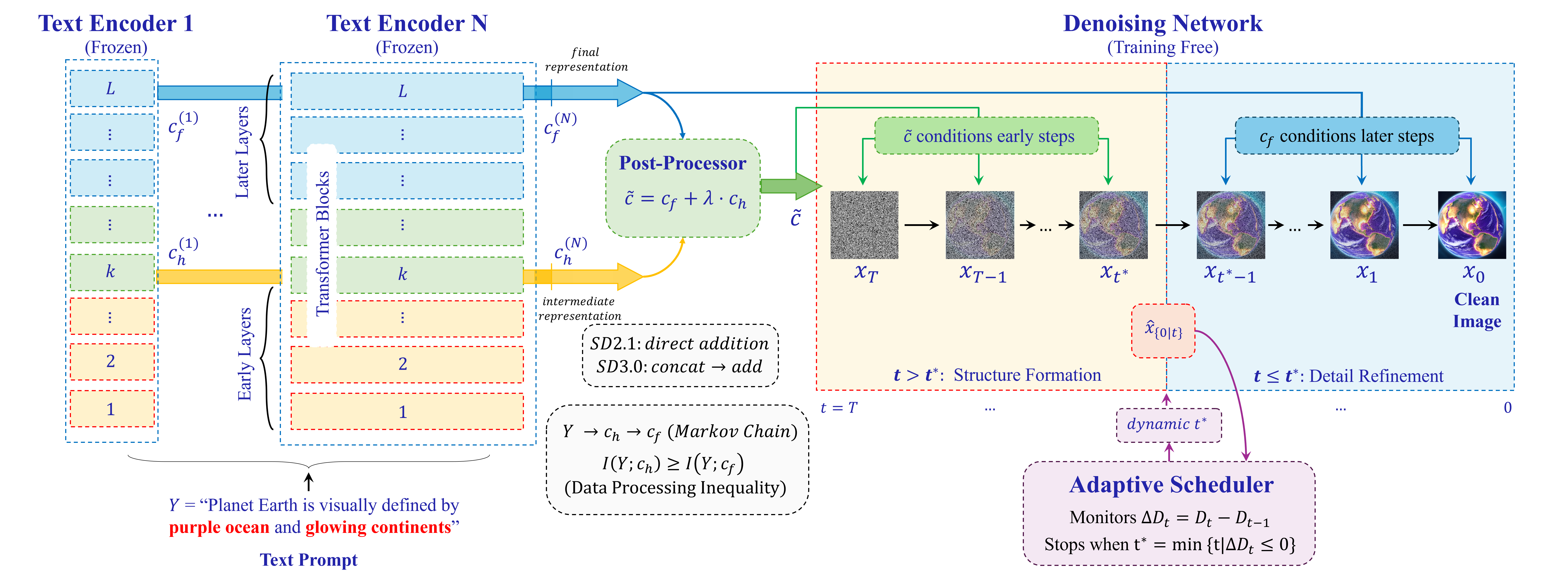
Text-to-image (T2I) diffusion models often fail to faithfully render explicit textual descriptions, instead defaulting to strongly learned visual priors due to a phenomenon referred to as concept association bias. We show that such bias is particularly strong for one-and-only (OAO) objects—entities that exist in a single canonical form, such as celestial bodies, landmarks, and famous artworks. The deeply ingrained visual identity for these concepts often resists modification through prompting alone. Addressing this challenge, we first identify through an information-theoretic analysis that the final text embedding of the text encoders discards concept-level information present in the earlier layers, reducing the mutual information available to the subsequent denoising process of T2I generation. We then propose Intermediate-Text-Representation (IR) guided diffusion, which injects intermediate hidden states of the text encoder into the conditioning signal during early denoising steps, recovering suppressed concepts without any additional training, optimization, or external models. To systematically evaluate the performance on the challenging task of aligning generative outputs with peculiar prompts for OAO objects, we introduce OAO-AttackBench, a benchmark comprising counterfactual prompts that directly contradict the core visual identity of OAO objects. Experiments on four benchmarks show that our method achieves up to a 19.1 percentage-point improvement in VQAscore for the task while preserving generation fidelity and human preference.
IR-Guided Diffusion